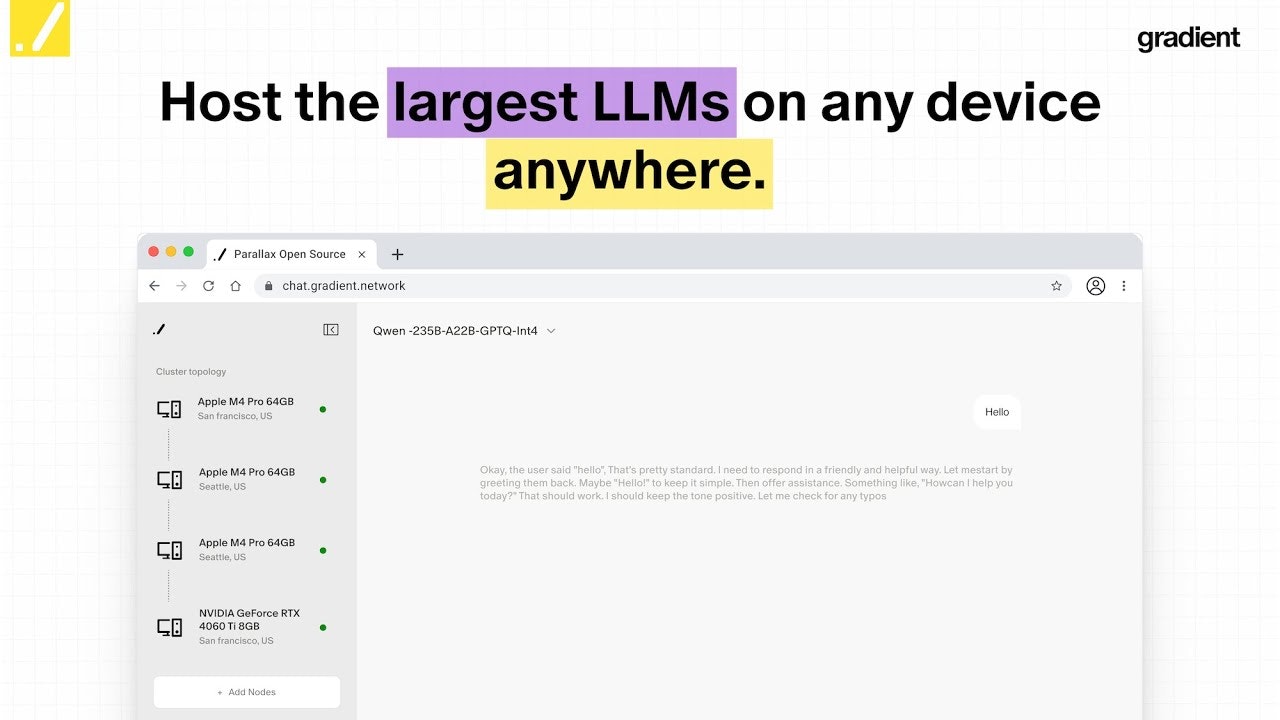
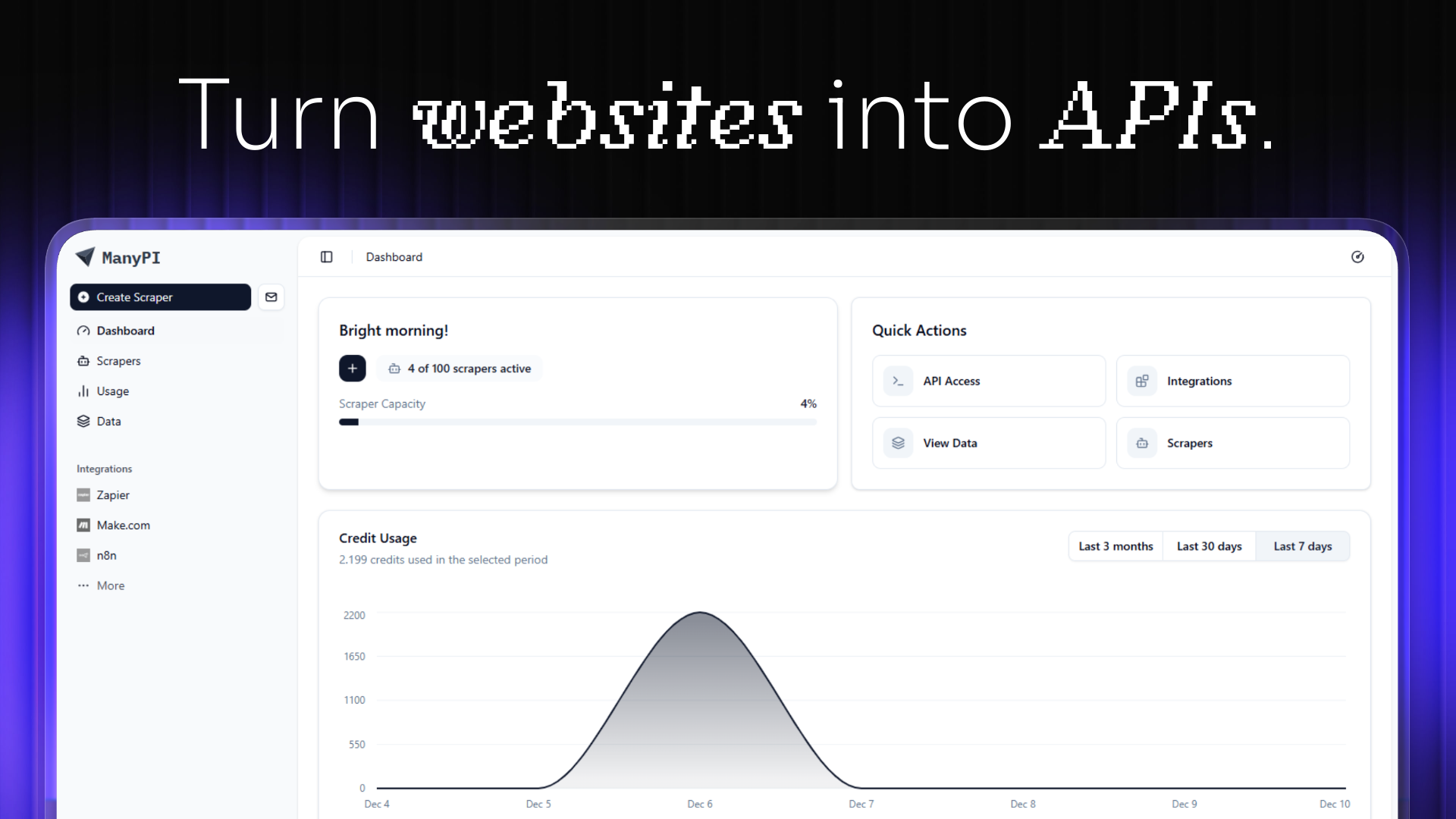
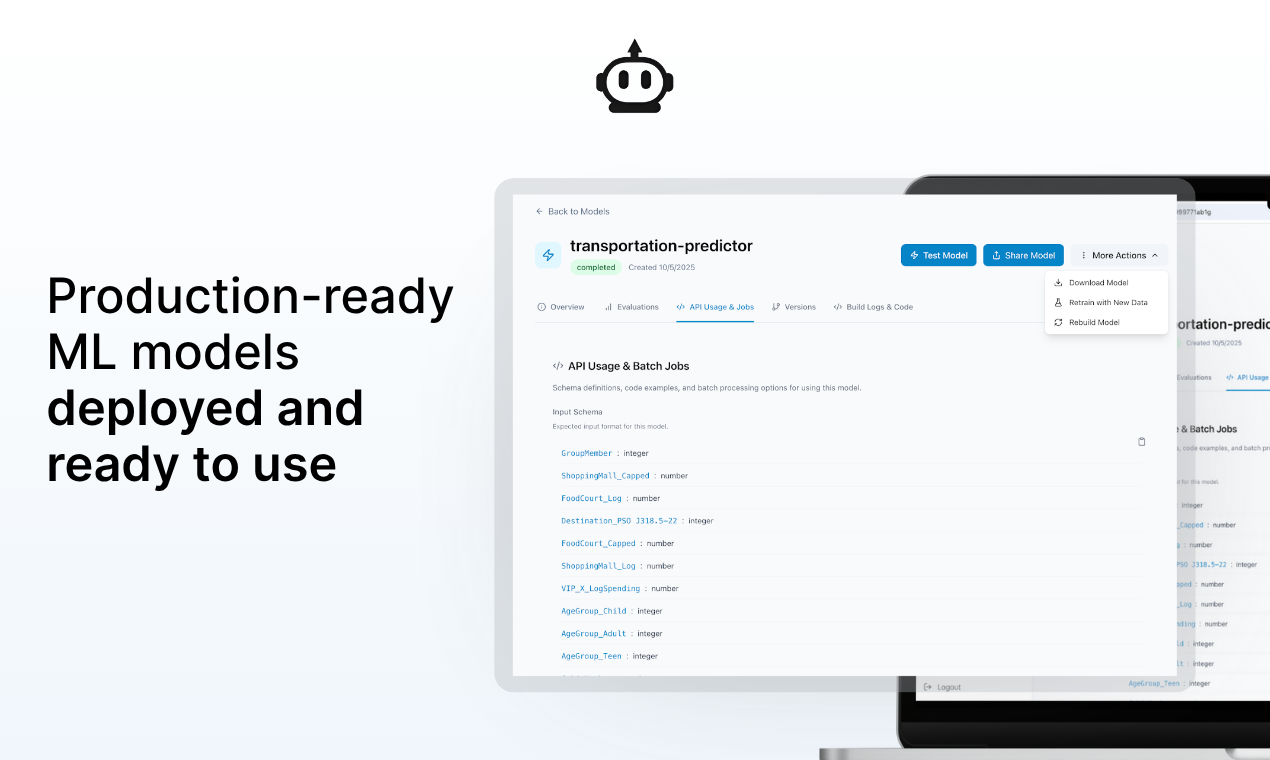
AI数据与模型

点击查看大图

点击查看大图

点击查看大图

点击查看大图
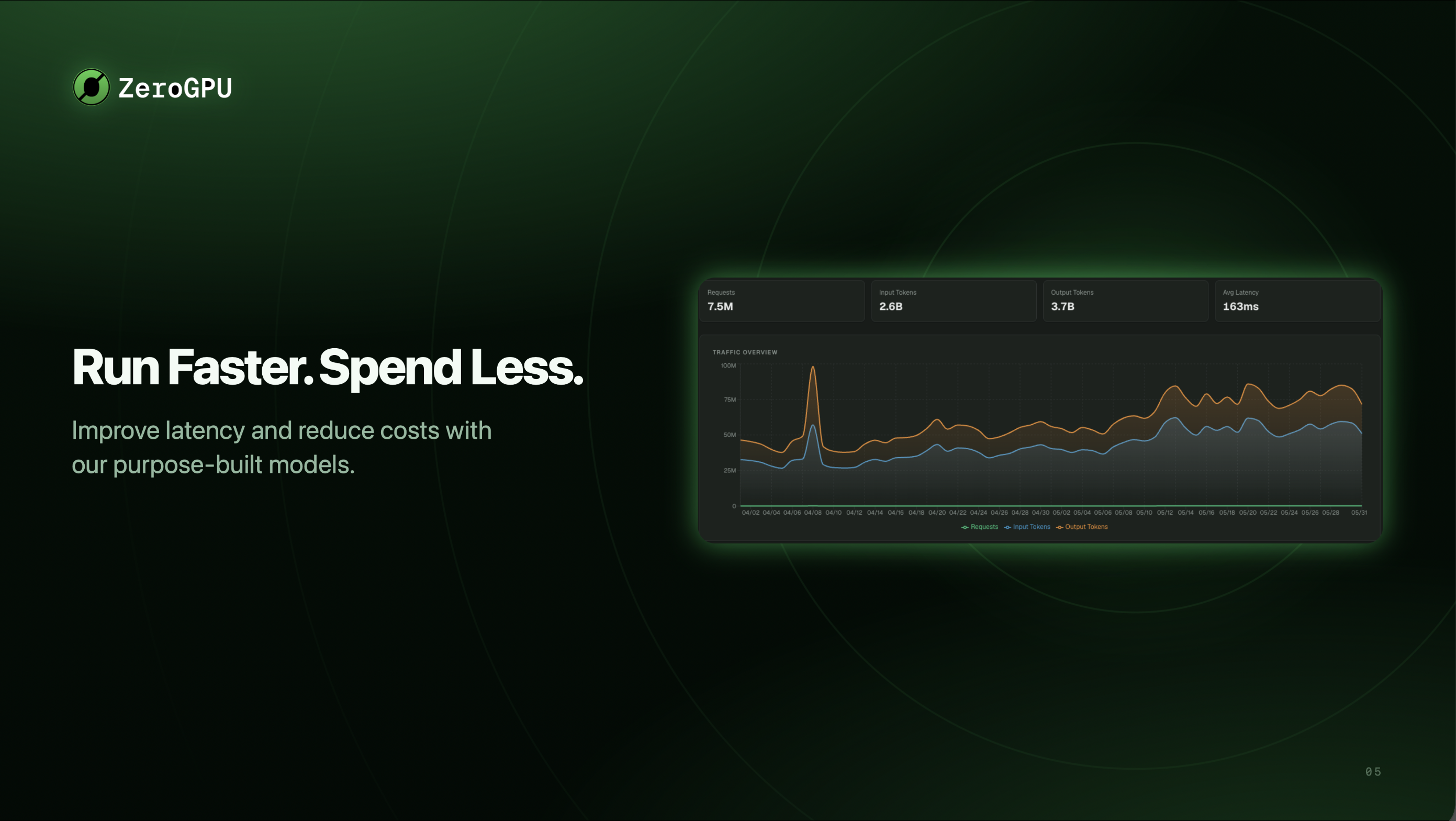
点击查看大图

点击查看大图
全面介绍
让 AI 推理更轻、更快、更经济 ✨
并非每个任务都需要最前沿的大模型。通过将日常 AI 工作负载从昂贵的前沿模型转移到专门设计的小型语言模型,我们帮助开发者在保持精准度的同时,显著降低推理成本并提升响应速度。
💡 核心优势:成本降低 50%+,速度提升 10 倍,可将 70-80% 的生产任务高效卸载至专门优化的边缘模型。
🎯 适合的场景
生产环境中的大部分 AI 流量都是结构化工作,这些任务非常适合由小型专业模型处理:
- 内容理解:文档分析、内容摘要、页面分类、信号提取
- 智能路由:意图检测、工具选择、查询路由、对话分类
- 安全与合规:PII 检测、内容审核、政策违规识别、品牌安全检查
- 实时决策:警报分类、可疑行为检测、轻量级风险评分
- 数据处理:网页内容获取与处理、多语言翻译、结构化数据提取
⚙️ 工作原理
- 分析工作负载
识别不需要前沿级推理能力的任务,确定优化机会。 - 运行专门模型
针对摘要、分类、信号提取、PII 检测等特定任务,使用专门构建的小型或纳米模型。 - 利用高效计算
在优化的服务器、经批准的边缘设备和云端回退之间智能分配工作负载,基于性能、可用性和成本进行调度。 - 衡量收益
实时追踪成本降低、延迟改善、避免的前沿模型调用次数以及模型性能指标。
🔒 隐私优先的设计理念
边缘计算不仅提升效率,更是对用户隐私的尊重:
- 不收集个人用户数据,不访问照片、联系人、文件或位置信息
- 推理负载完成后不会存储在设备上
- 设备仅作为突发计算资源,一次只处理一个请求
- 电池感知、温度感知和网络感知,仅在条件健康时运行
🚀 无缝集成体验
使用熟悉的 API 模式即可接入,无需重构现有应用:
- OpenAI 兼容接口:支持标准的聊天和响应 API 格式
- 丰富的模型目录:提供专门的小型语言模型和纳米模型
- 项目级 API 密钥:便于团队协作和权限管理
- 全面的分析面板:实时查看使用量、延迟和成本节省数据
🌱 更智能的 AI 基础设施:未来的 AI 不仅仅是更大的模型,而是更聪明的推理方式。通过结合专门模型、优化服务器和边缘计算,我们构建了一个更可持续、更高效的 AI 推理层。
产品评分
暂无评分
登录后即可评分